The OLAMIP standard is designed to make websites readable by large language models (LLMs). More importantly, it aligns with core machine learning principles: the ways models learn, generalize, and reason from structured data.
Here’s how:
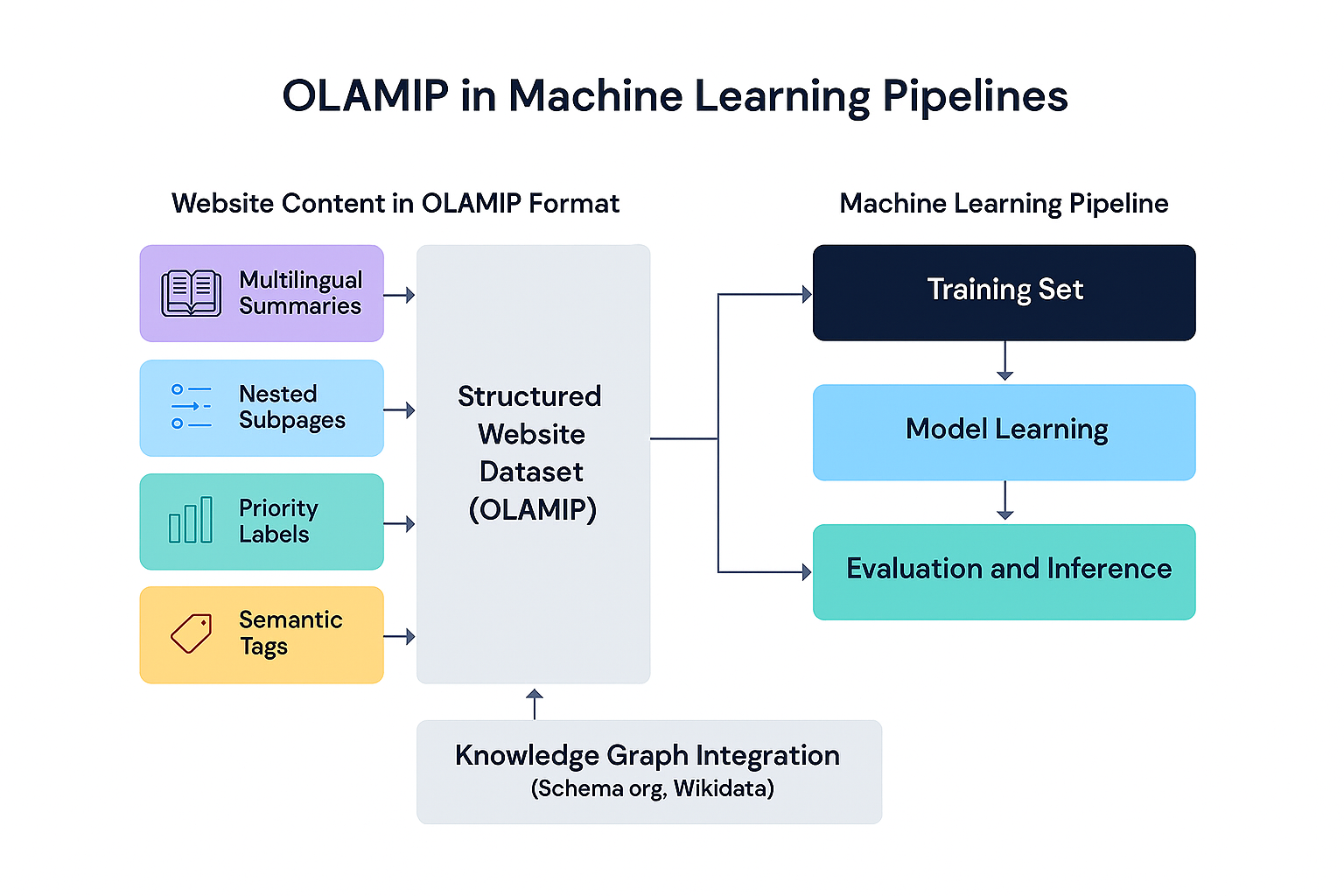
1. Structured, Labeled Data → Supervised Learning
Machine learning models perform best when trained on clean, labeled datasets. OLAMIP transforms a website into exactly that:
- Structured JSON entries for each important page
- Explicit fields such as title, tags, priority, and summary
- Optional multilingual summaries for parallel cross‑language training
Each entry becomes a labeled example of a page’s meaning and purpose, turning your site into a supervised training corpus rather than an unstructured HTML document.
2. Feature Engineering → Semantic Fields
Feature engineering extracts meaningful signals from raw data. OLAMIP provides these signals natively:
- Priority acts as a relevance or importance weight
- Tags provide topical clustering and domain cues
- Semantic fields (schema.org, RDF, Wikidata) encode entity relationships
These features help models learn faster, reduce ambiguity, and improve retrieval accuracy.
3. Hierarchical Structure Through Sections & Subsections
Modern ML architectures learn more effectively when information is organized hierarchically. OLAMIP reflects real website structure through sections and subsections, giving models a clear sense of context.
How OLAMIP Represents Hierarchy
- Sections act as top‑level categories (e.g., “Laptops”, “Support”, “Documentation”)
- Subsections provide nested grouping within each section (e.g., “Gaming Laptops”, “Ultrabooks”, “API Reference”)
- Entries live inside these subsections, inheriting context from the structure above them
This structure provides the same hierarchical clarity that a children field would offer, but in a cleaner, more maintainable format.
{
"sections": [
{
"title": "Laptops",
"subsections": [
{
"title": "Gaming Laptops",
"entries": [
{ "title": "Model A", "url": "/product/a", "summary": "..." },
{ "title": "Model B", "url": "/product/b", "summary": "..." }
]
}
]
}
]
}
4. Multilingual Training → Cross-lingual Alignment
OLAMIP supports multilingual AI development through optional multilingual summaries. These enable:
- Parallel corpora for multilingual model training
- Cross‑lingual retrieval and translation tasks
- Reduction of English‑centric bias in datasets
This aligns with the growing need for globally capable AI systems.
5. Knowledge Graph Integration → Semantic Reasoning
The semantic fields in OLAMIP links entries to structured knowledge sources:
- Schema.org types (e.g., Product, Event, HowTo)
- Wikidata entities (Q‑codes for real‑world concepts)
- RDF/JSON‑LD resources for machine‑readable relationships
These connections support:
- Entity disambiguation
- Symbolic reasoning
- Fact grounding
- Knowledge graph alignment
This is essential for advanced AI systems that combine statistical learning with structured reasoning.
6. Curriculum Learning → Priority-Based Sampling
Curriculum learning trains models on the most important or foundational examples first. OLAMIP’s priority field enables this directly:
- High‑priority pages are sampled more frequently
- Medium and low priority entries support generalization
This improves training efficiency and ensures models focus on your most authoritative content.
7. Continuous Learning → Real-Time Updates
OLAMIP files can be updated regularly:
- New pages are added
- Summaries are refined
- Semantic links evolve
Delta Updates as an ML-Aligned Mechanism to support real-time adaptation, OLAMIP includes an incremental update mechanism through olamip-delta.json. Instead of reprocessing the full dataset, ML pipelines can ingest only the changes, new entries, modified summaries, or removed pages. This mirrors how modern ML systems handle streaming data, enabling efficient retraining and keeping models aligned with the latest version of your site. The main olamip.json remains the complete, authoritative dataset, while deltas act as compact, ML-friendly update packets.
Summary
By adopting OLAMIP, your website becomes:
- A structured dataset for AI training
- A semantic node in the global knowledge graph
- A multilingual resource for diverse users
- A hierarchically organized corpus for contextual modeling
This isn’t just SEO; it’s ML optimization at the source.